G1人形机器人二次开发
机器人开发UnityGodotAI-AgentPython人脸识别
对宇树G1人形机器人进行二次开发,包括智能问答、智能交互、访客预约、展厅讲解、舞蹈动作控制表演等,外接硬件设备设计与适配。
技术方案
- 本地部署人脸识别算法+TTS进行人脸识别和访客引导
- 本地部署RAG大模型与知识库,支持上传文档多媒体文件等
- 本地部署开发TTS,支持无限合成内容长度和时长,支持中英混读,支持标点和电话等智能解析,RTX4060Ti上实测首字20-50ms内回复
- 本地部署ASR识别,支持Websocket长连接流式识别,支持HTTP请求本地识别
- 机器人客户端ASR到LLM以及TTS全流程流式响应,最短反馈时间<1s,对速度和优化进行极致优化
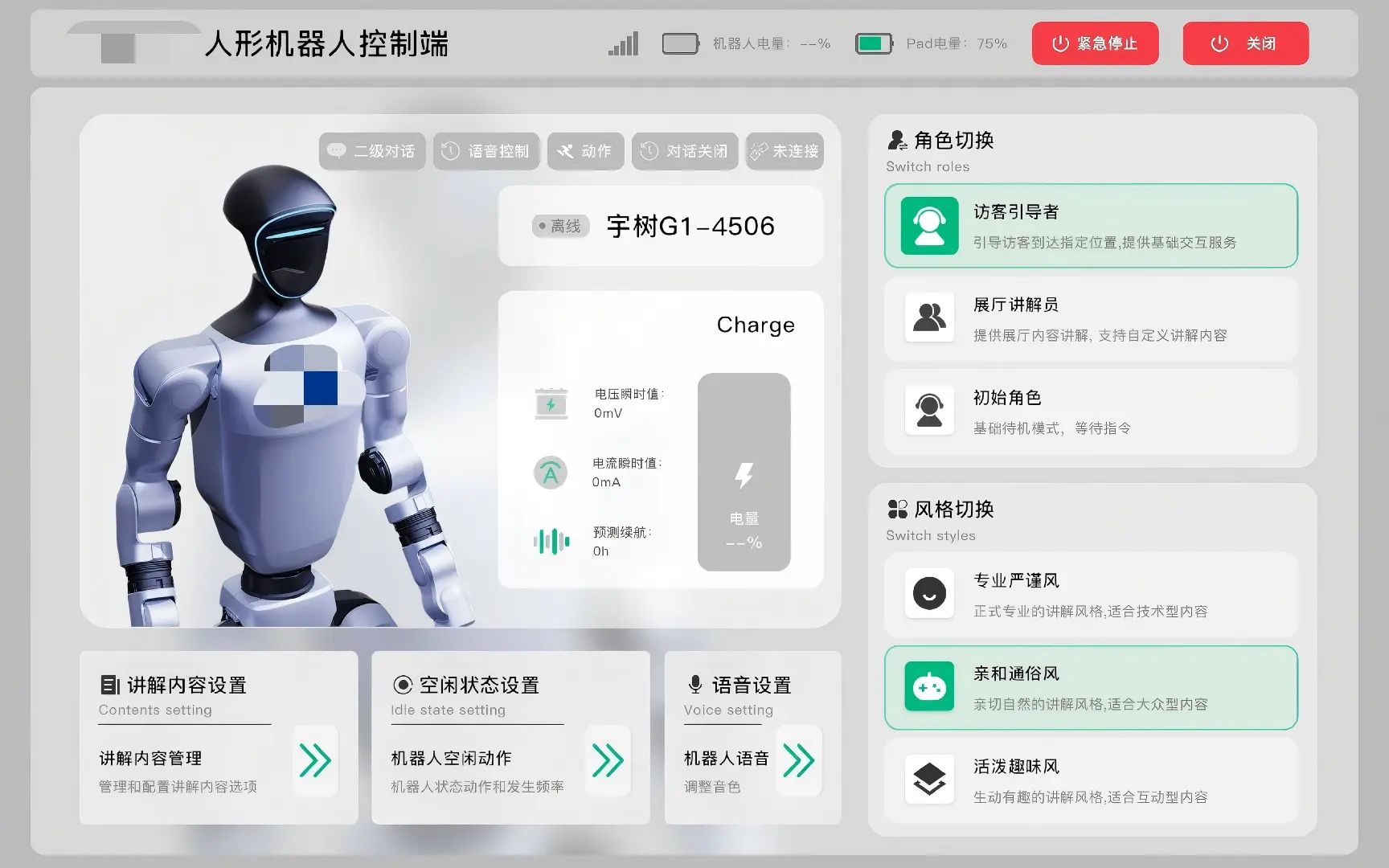
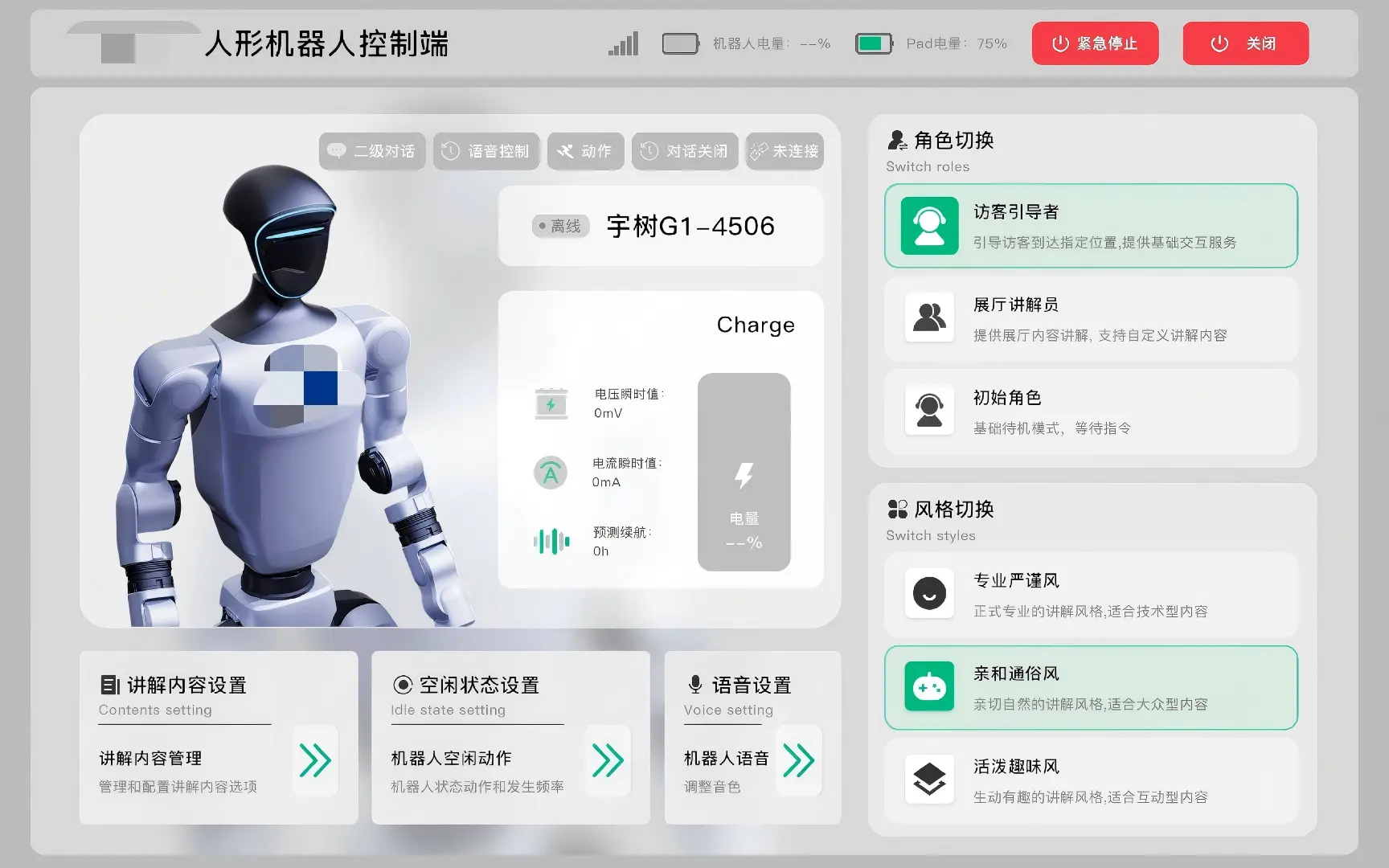
- 配备Unity开发的Android平台的Pad控制端,除了语音输入外还支持Pad进行同步控制
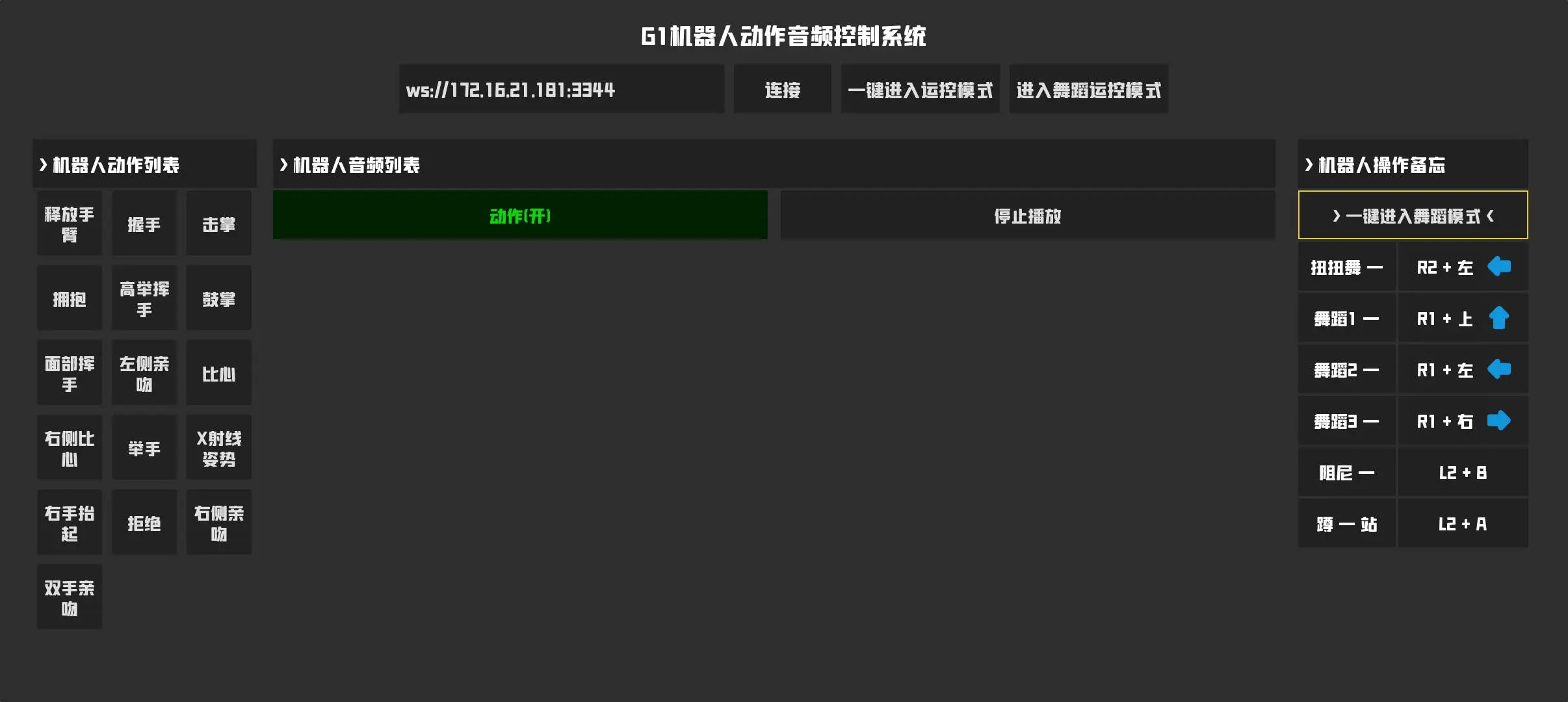
- 使用Godot开发Andorid机器人动作和舞蹈控制端,控制器人切换不同运控模式和动作以及舞蹈和语音播放等,适合表演使用
- 语音交互全链路:自研 VAD 静音检测 → 流式 ASR 语音识别(WebSocket 优先 + 机器人内置 ASR 兜底双通道)→ LLM 大模型对话(DeepSeek + 自建后端双路由)→ 伪流式 TTS 分段合成与播放,实现 <2s 首字延迟的实时语音对话
- 语音指令控制系统:基于 YAML 规则引擎 + 关键词匹配实现 30+ 条语音指令意图识别,覆盖运动控制(前进/后退/转向/阻尼/走跑切换)、肢体动作(挥手/握手/拥抱/飞吻等 13 种)、角色风格切换、对话开关等,支持前端远程启停单条指令
- 机器人运控集成:通过 DDS 协议与 G1 底层通信,封装 LocoClient 运动控制(FSM 状态机切换/速度矢量控制)与 ArmActionClient 手臂动作,实现语音→动作的端到端闭环,包含自动姿态切换逻辑(阻尼→站立→走跑)
- WebSocket 实时服务:基于 asyncio + websockets 构建双向通信服务,支持前端远程控制(模式切换/TTS 播报/打断/配置热更新)、机器人状态实时推送(电量/信号/运动状态/运行时状态),具备广播与点对点消息路由能力
- 多模式多角色架构:设计待机/朗读/问答三种运行模式 + 5 种角色风格(初始角色/展厅讲解员/访客引导者 + 专业严谨/亲和通俗/活泼趣味),运行时可通过语音或 WebSocket 热切换,角色切换自动触发个性化开场白
- 系统监控闭环:实现 WiFi 信号强度(dBm→百分比转换 + SSID 读取,支持 iw/iwconfig//proc/net/wireless 多源降级)、后端服务健康检测(TCP 建连延时探测 + 缓存防抖)、机器人电量采集(DDS 订阅 BMS 状态),统一通过 WebSocket 推送监控面板
- 音频设备管理:PulseAudio 自动化配置,启动时自适应检测 USB/板载声卡并设定默认输入输出设备,支持音量远程调节与音频服务 systemd 热重启
- 展厅业务逻辑:集成人脸识别结果处理,根据身份类别(员工/已预约访客/审核中访客/陌生人)执行差异化引导流程与门禁联动;对话历史记录持久化与前端检索
- 工程化设计:分层架构(adapters/services/config/ai_chatbot/app)+ 环境变量配置分离(.env.local/.env.dev)+ systemd 服务部署 + 异步并发编排(asyncio 全链路),兼顾机器人端与 WSL 开发环境兼容